
The Semantic Web, HTML and XML: An Example
by K. Yue
January 16, 2002
copyright 2002
Zero draft: December 28, 2002
First draft: January 16, 2002
1. Introduction
The traditional Web is based on the markup language HyperText Markup Language (HTML). HTML provides markup information to Web browsers on how to display documents. For example, the HTML element <i> informs the browser that the element body should be displayed in italic. Thus, HTML markup elements are used to convene display information for one particular type of client: the Web browser. The Web browser in turn uses the document in one way: display it for the users to view.
A HTML file includes the content of the document (content) and HTML markups for display (presentation). Contents and presentations are intermingled together. Since the contents usually have flat structures, it is difficult for computer programs to extract semantic information from HTML files. For example, consider the following HTML code:
<b>CSCI 4230 Internet Application Development</b>
The browser knows to display it in bold and it may be possible or even easy for the users to understand that it refers to a course. However, it will obviously be difficult for computer programs to do so since programs are in general not as good in processing unstructured data. As a result, it is difficult for programs to extract semantic data from HTML to repurpose the contents, such as to change the presentation format, or to store selected data into a database. For example, without further information, a search engine looking for courses will have a hard time to figure out that the HTML code refers to a course.
Lacking meaning, the Web based on HTML is not semantic. A semantic Web requires contents that are meaningful and easy to process and that is where XML comes into the picture. In XML, the same information may be stored as:
<course>
<rubric>CSCI</rubric>
<number>4230</number>
<title>Internet Application Development</title>
</course>
Obviously, the XML code can equally easily be read by human being or processed by computer programs. As a result, it is much easier to repurpose the contents, changes the presentation format, or extract relevant information.
Basing on HTML, the first stage of the Internet basically uses only one kind of client, the browser. In the semantic Web based on XML, you may have any kind of clients, extracting and repurposing the contents to fit the application needs. Instead of using only traditional browsers, clients can be both human or machines: mobile phones, personal digital assistants, net appliances, intelligent appliances, robots, intelligent agents, etc.
In short, the semantic Web will greatly expand the scope and usefulness of the Internet by providing the possibilities of unlimited kinds of clients and enhancing interconnectivity. XML is the basis for the architecture of the semantic Web. In this article, we present a short example to illustrate the difficulty of HTML scalping for data extraction and the relative ease if XML is used instead.
2. HTML Scalping
HTML scalping attempts to extract information from HTML documents based on their display structures. To extract contents from HTML documents, the following steps will be needed:
As an example, we will write a program to get the quote of a given stock symbol (such is IBM) form Yahoo.
2.1 Study the HTTP request formats required
The first step is to study the source Web site and experiment with the right format to submit the HTTP request. For example, we may use the following URL to get the quote of IBM from Yahoo.
http://finance.yahoo.com/q?s=ibm&d=v1
The result may be displayed as below.
We may conjecture that to get the quote of any stock, we may simply replace "IBM" by the stock symbol. The HTTP request can thus be make through the GET method using an URL with the parameter "s" set to the desired stock symbol.
2.2 Retrieve the HTML document using the HTTP request
Different languages provide different libraries, classes, modules and functions for supporting HTTP clients. For example, for Perl, we may use the module LWP::Simple.
use LWP::Simple;
...
my $body = get("http://finance.yahoo.com/q?s=$symbol&d=v1");
In the code, we can note the followings:
2.3 Study the format of the HTML document
The next step is to study the contents of the HTML document to discover any pattern useful for extracting the required information. This includes the followings.
In our example, the HTML contents stored in the Perl variable $body can be seen here (converted to HTML format with line numbers added).
The table that contains the required information is shown below.

Suppose we only want the last trade time and quote. We should study the HTML code that contains this table and identify a useful pattern for extraction. Unfortunately, selecting a good pattern is an art usually done by trial and error. A correct pattern will need to avoid the two common types of errors:
For example, we may find out the required data is stored in the HTML code.
<a href="/q?s=IBM&d=t">IBM</a></td><td nowrap align=center>4:01PM</td><td nowrap><b>120.31</b></td><td nowrap><font color=ff0020>-1.83</font></td><td nowrap><font color=ff0020>-1.50%</font></td>...
2.4 Extract the required contents based on the HTML format
The Perl code for extracting the trade time and quote from the Perl variable $body into the two predefined Perl variables $1 and $2 may be:
$body =~ /<a[^>]*?$symbol[^>]*?>$symbol.*?<td[^>]*?>(.*?)<\/td><td[^\/]*>(.*?)<\//si;
The detailed explanation of this Perl code is beyond the scope of this article. Roughly, the actions taken by Perl are listed below. You may not want to follow through all details but they serve to show the flavor and complexity of the process.
In our example using IBM, if this is successfully executed, the two Perl variables $1 and $2 will have the string values of "4:01PM" and "120.31" respectively.
A full command line program getYahooQuote.pl may be:
use strict;
use LWP::Simple;
# Yahoo site for getting the quote for "IBM"
# http://finance.yahoo.com/q?s=IBM&d=v1
# getYahooQuote.pl stocksymbol
# by Kwok-Bun Yue
# Get stock symbol
@ARGV < 1 && die "Usage: getYahooQuote.pl stocksymbol\n";
my $symbol = $ARGV[0];
# Get quote table.
my $body = get("http://finance.yahoo.com/q?s=$symbol&d=v1");
# Extract information
$body =~ /<a[^>]*?$symbol[^>]*?>$symbol.*?<Td[^>]*?>(.*?)<\/td><td[^\/]*>(.*?)<\//si;my
$quote = $2;
my $quoteTime = $1;
# Show result;
print "Stock $symbol at $quoteTime: \$$quote";
exit 0;
Here is a session of running the program:
>getYahooQuote.pl IBM
Stock IBM at 4:01PM: $120.31
>getYahooQuote.pl orcl
Stock orcl at 4:00PM: $16.27
Once the information is extracted, it is fairly easy to modify the program to display them in other context. For example, the program can readily be converted into a CGI-Perl program.
2.5 Problems of HTML scalping
The example clearly illustrates the problems of HTML scalping programs.
(1) They are difficult to write.
There are no mechanic way to identify a useful pattern for extraction. The selected pattern may not always work. The pattern may be difficult to implement. Look at the complexity of the Perl pattern in the example, which only extract two values! Imagine what may happen if more complicated data must be extracted.
The flexibility of HTML also adds significantly to the difficulty. For example, it is optional to end a <td> tag by a </td> tag as the next <td> implicitly ends the previous <td> tag. If Yahoo selects to remove </td>, the display will remain unchanged but our program will no longer work. This is made worse by the factor that browsers try to recover from errors. Whatever changes that create errors in the HTML code may still be viewed acceptably in the browsers may create havoc for the programs.
(2) They are fragile to change.
If the source site decides to change the display format, the programs may break. In our example, if Yahoo changes to display the time in bold, the program will not work properly. Unfortunately, Web sites change the format of their pages very frequently and these programs will become a headache to maintain.
(3) They are not efficient.
The inefficiency comes in two ways. First, the 'signal to noise' ratio is low. HTML documents contain the information the Web sites want the user to view, which may be much larger than the information that the user is interested to extract. In our example, the size of the useful information is 12 Bytes: "4:01PM" and "120.31". On the other hand, the size of the HTML document body is 12,464 Bytes, more than a thousand time larger. This low signal to noise ratio increases network communication time. The programs take longer to receive the HTML contents.
Second, since the source content is large and the pattern may be quite complicated, it can be expected that the program takes more time for the extraction.
To summarize, extracting data from HTML documents is difficult, fragile and inefficient. HTML is not the right tool for supporting a semantic Web where data extraction and searching should be easy, reliable and efficient.
3. XML and the Semantic Web
To support the semantic Web, XML is much more suitable. XML is a meta-language used to define markup languages for different applications. Since XML developers can invent their markup elements, XML documents can be much more meaningful.
To continue our example, instead of the Yahoo site above that serves HTML contents, we may find an XML server that serves up XML contents like:
<?xml version="1.0"?>
<!DOCTYPE stock SYSTEM "http://dcm.uhcl.edu/yue/xml/stockquote/stocks.dtd">
<stocks>
<stock>
<symbol>IBM</symbol>
<companyname>INTL BUS MACHINE</companyname>
<lastprice>120.31</lastprice>
<lasttradedate>1/11/2002</lasttradedate>
<lasttradetime>4:01PM</lasttradetime>
<change>-1.83</change>
<percentchange>-1.50%</percentchange>
<volume>4797400</volume>
<averagedailyvolume>7312909</averagedailyvolume>
<bid>N/A</bid>
<ask>N/A</ask>
<previousclose>122.14</previousclose>
<todayopen>121.50</todayopen>
<dayrange>120.28 - 122.18</dayrange>
<fiftytwoweekrange>87.4900 - 126.3900</fiftytwoweekrange>
<earningspershare>4.50</earningspershare>
<peratio>27.14</peratio>
<dividendpaydate>Dec 10</dividendpaydate>
<dividendpershare>0.56</dividendpershare>
<dividendyield>0.46</dividendyield>
<marketcapitalization>207.3B</marketcapitalization>
<stockexchange>NYSE</stockexchange>
</stock>
</stocks>
This XML document is so simple that it is mostly self-explanatory.
To continue the example, the following is an equivalent program that extract stock information using the service of a simple XML server.
Use strict;
use LWP::Simple;
# The site for getting the quote for "IBM"
# http://dcm.uhcl.edu/yue/courses/resources/xml/stockquotexml.pl?stocks=IBM
# getXMLQuote.pl stocksymbol
# by Kwok-Bun Yue
# Get stocksymbol
@ARGV < 1 && die "Usage: getYahooQuote.pl stocksymbol\n";
my $symbol = $ARGV[0];
# Get quote table.
My $body = get("http://dcm.uhcl.edu/yue/courses/resources/xml/stockquotexml.pl?stocks=$symbol");
$body =~ /<lastprice>(.*?)<\/lastprice>.*?<lasttradetime>(.*?)<\/lasttradetime>/si;
my $quote = $2;
my $quoteTime = $1;
# Show result;
print "Stock $symbol at $quoteTime: \$$quote";
exit 0;
There are only a few changes.
(1) The source URL
A very simple stock quote XML server was written (which actually uses Yahoo's service) with the URL for quoting IBM:
http://dcm.uhcl.edu/yue/courses/resources/xml/stockquotexml.pl?stocks=IBM
It is displayed in IE 5.x as:
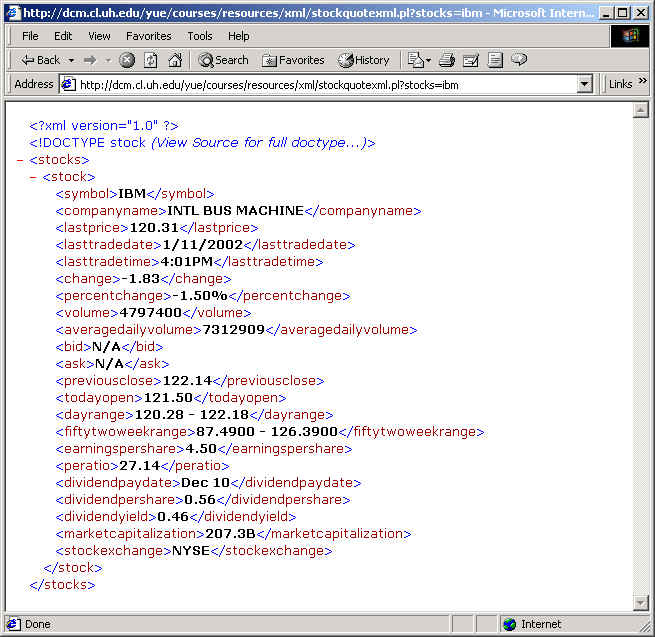
The new Perl program uses this URL as the argument for the get method of LWP::Simple.
(2) The Perl pattern for extraction.
The new pattern is simply:
$body =~ /<lastprice>(.*?)<\/lastprice>.*?<lasttradetime>(.*?)<\/lasttradetime>/si;
This simply put the bodies of the elements <lastprice> and <lasttradetime> into the Perl variables $1 and $2 respectively.
3.1 Advantages of using XML
The example illustrates why XML is much superior in supporting the semantic Web.
(1) XML programs are easier to write.
XML provides a much more restrictive structure than HTML which facilitates information extraction. Using our example, the Perl pattern is now much simpler. Furthermore, refining the program to show other information such as changes and volumes are also straightforward. In fact, it will be easier to rewrite the program to display quotes from multiple stock symbols, which the simple XML server supports.
Furthermore, XML is much stricter than HTML. For example, to comply with XML, a <td> must end with a </td> tag. The problem of missing </td> in HTML problem cannot happen in XML. If an XML document has an error, it will not be displayed by an XML enabled browser.
XML is relatively easy even if complicated data extracted is demanded. Unlike HTML, XML is designed to be easy for parsing. There are standards and many available XML parsers to assist data extraction.
(2) XML programs are more reliable.
The structures of XML applications are defined by Document Type Definition
(DTD), which usually change very slowly and mildly. XML is used for data transmission
and most content providers have every incentive to make the DTD as open and
stable as possible. This is in contrast with the rapid changes in display formats
by many Web sites, which may break the HTML scalping programs.
(3) XML programs are more efficient.
HTML content providers usually manage the 'real estate' very carefully since their business models are based on its use. The browsers display what the providers want the users to see, which are not necessary the same as what the users want to see. This explains the low signal to noise ratio. XML documents may not even be viewed directly by the user so the content providers do not have full control of what will be displayed. It may just be consumed by programs and not displayed at all. As such, XML documents contain mostly useful data but not content provider added contents that may have no value to the client.
As a result, the size of the XML contents are usually smaller when compared to the HTML contents. In our example, the size of the XML contents is 1,007 Bytes, as compared to 12,464 Bytes for HTML contents.
The smaller sizes make both transmission and processing more efficient. Furthermore, XML has a much stricter syntax and structure and can thus be processed much more effective. This is easy to see in our example by comparing the complexity matching patterns using for HTML and XML.
Conclusion
This article provides a concrete programming example to illustrate the advantages of using XML to support the semantic Web.