Evolution of Software Architectures
by K. Yue
August, 2002, last modified: july 1, 2004
copyright 2002-4
1. Introduction: Why semantic Web?
- Intelligent processing of information will be possible.
- Low noise to signal ratio.
- More efficient transmission.
- Easier to process.
- More personalized information.
- Explosive growth of information communication.
- Internet data will increasingly be processed by machines, and not viewed
by human beings.
- There will be much richer way for human computer interaction (HCI).
- Huge number of new applications will appear.
2. Evolution of Software Architectures
- Software architecture has changed during the last 40 years.
- A very coarse evolution will be shown.
2.1 Phase 1: Mainframe-based
- Highly centralized.
- Very thin clients: dumb terminals.
- Largely disconnected to outside of the organization.
2.2 Phase 2: Traditional 2-tiered Client and Server
- Fat clients: PC.
- Proprietary protocols.
- Many dedicated servers.
- Access largely within the organization.
- Interoperability not yet a large issue.

Figure 1 Basic organization of traditional 2-tiered client
and server system.
2.3 Phase 3: Web-Based N-tiered Client-Server
- Open Internet protocols.
- Middle layer for definition of business logic: better software development
and management.
- Serving clients outside of the organization: Internet.
- The browser was the "universal client".
- Thinner clients: no need of complicated proprietary client software.
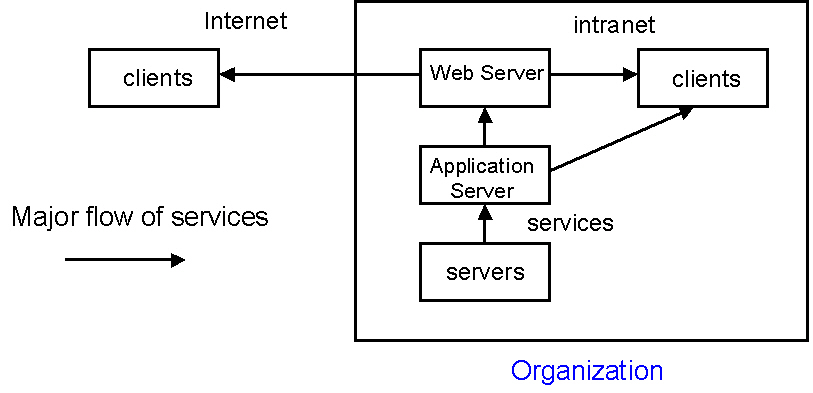
Figure 2 Web-based N-tiered client and server system
2.4 Phase 4: Web-Centric Applications
- Potentially thin clients.
- Clients and servers can be blurred.
- Services in and out of the organization.
- Data/services from many servers, inside and outside of the organization.
- No single organization can provide 'everything.'
- Much more personalized software.
- XML is a cornerstone technology of Web-Centric
architectures.
- Web services become popular.
- Semantic web connects applications.
- Peer-to-peer technology.
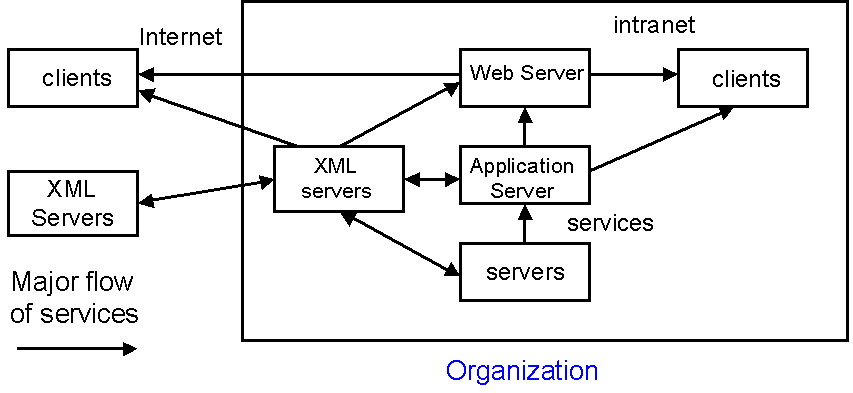
Figure 3 Web-centric system